
- Intel Shared GPU memory benefits LLMs
- Expanded VRAM pools allow smoother execution of AI workloads
- Some games slow down when the memory expands
Intel has added a new capability to its Core Ultra systems which echoes an earlier move from AMD.
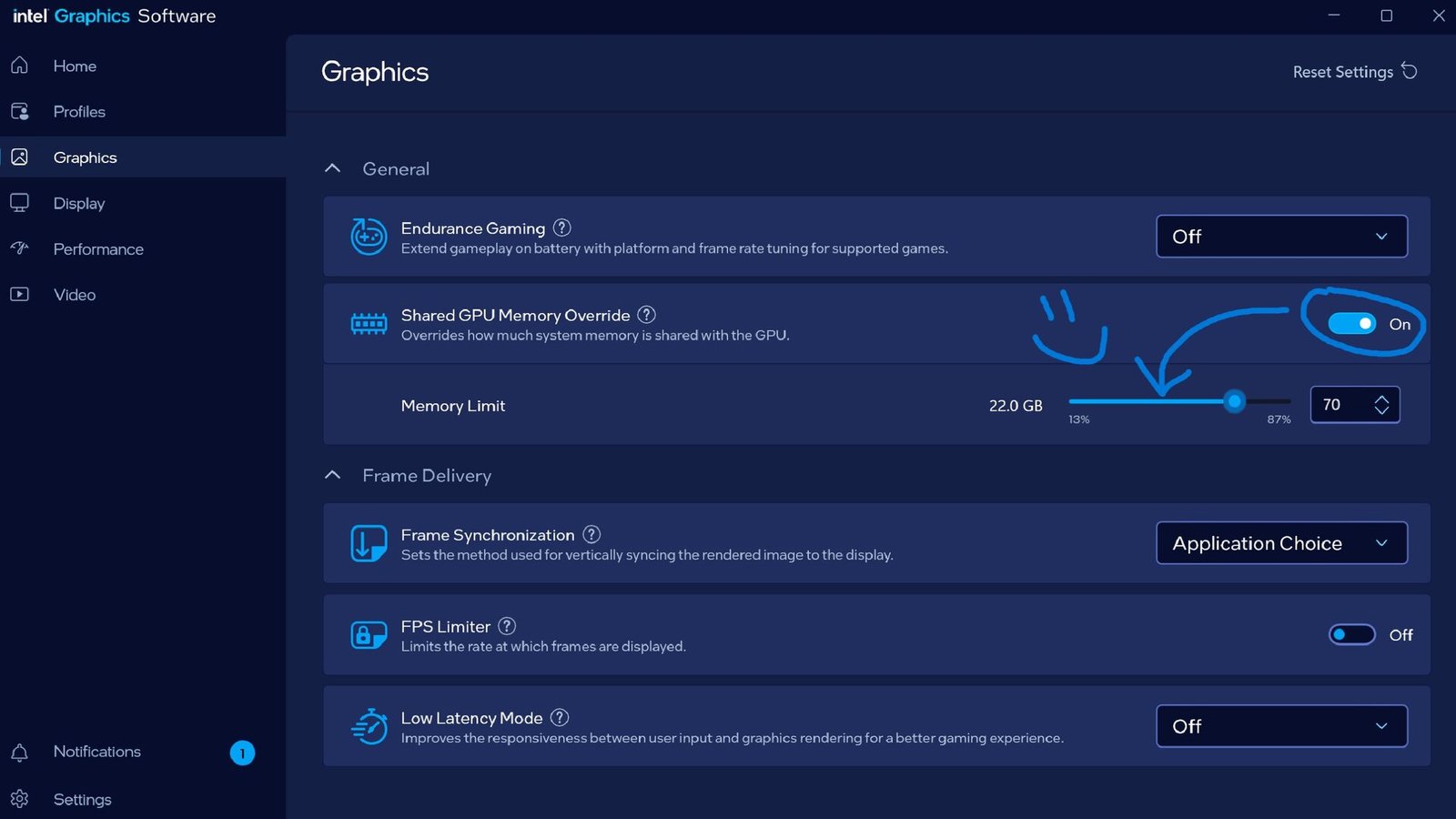
The feature, known as “Shared GPU Memory Override,” allows users to allocate additional system RAM for use by integrated graphics.
This development is targeted at machines that rely on integrated solutions rather than discrete GPUs, a category that includes many compact laptops and mobile workstation models.
Memory allocation and gaming performance
Bob Duffy, who leads Graphics and AI Evangelism at Intel, confirmed the update and advised that the latest Intel Arc drivers are required to enable the function.
The change is presented as a way of enhancing system flexibility, particularly for users interested in AI tools and workloads that depend on memory availability.
The introduction of extra shared memory is not automatically a benefit for every application, as testing has shown that some games may load larger textures if more memory is available, which can actually cause performance to dip rather than improve.
AMD’s earlier “Variable Graphics Memory” was framed largely as a gaming enhancement, especially when combined with AFMF.
That combination allowed more game assets to be stored directly in memory, which sometimes produced measurable gains.
Although the impact was not universal, results varied depending on the software in question.
Intel’s adoption of a comparable system suggests it is keen to remain competitive, although skepticism remains over how broadly it will benefit everyday users.
While gamers may see mixed outcomes, those working with local models could stand to gain more from Intel’s approach.
Running large language models locally is becoming increasingly common, and these workloads are often limited by available memory.
By extending the pool of RAM available to integrated graphics, Intel is positioning its systems to handle larger models that would otherwise be constrained.
This may allow users to offload more of the model onto VRAM, reducing bottlenecks and improving stability when running AI tools.
For researchers and developers without access to a discrete GPU, this could offer a modest but useful improvement.


